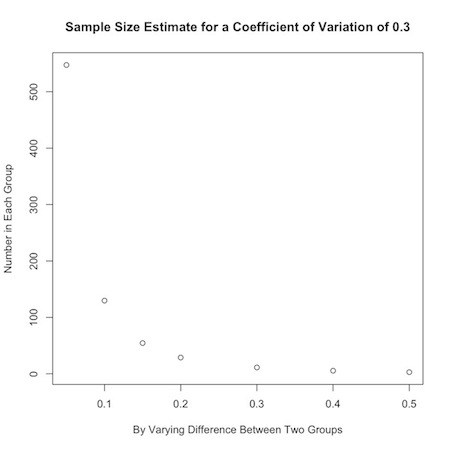
COOKING A SAMPLE SIZE
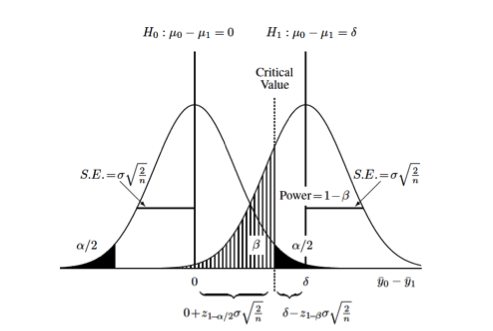
Difference between two groups on continuous measurement
Difference between two groups on continuous measurement
Difference between two groups on continuous measurement
Difference between two groups on continuous measurement
Difference between two groups on continuous measurement
Difference between two groups on continuous measurement
Difference between two groups on continuous measurement
- \[ n_{group}=\frac{16(c.v.)^2}{(ln(\mu_0)-ln(\mu_1))^2} \\ n_{group}=\frac{16(c.v.)^2}{(ln(r.m.))^2} \]
R function
1 2 3 4 | |
1 2 3 4 5 6 | |
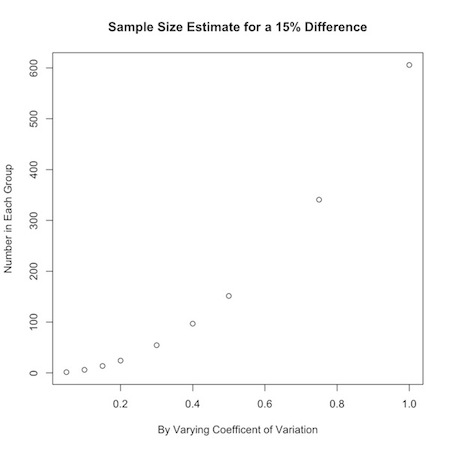
1 2 3 | |